

协议解析器java-java 解析hl7协议
01
摘要
网络爬虫,又称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。百度、Google等搜索引擎都会使用爬虫访问收集整理互联网上的网页、图片、视频等内容,然后分门别类建立索引数据库,使用户能在搜索引擎中搜索到网站的网页、图片、视频等内容。
提起爬虫,大多数人了解的更多是Python爬虫,Python在处理网页方面,有着开发简单、便捷、性能高效的优势,但是在处理复杂页面、需要解析网页内容生成结构化数据或者对网页内容精细的解析时,Java更胜一筹。但最主要的原因还是,我Java用的更好。
02
WebCollector介绍

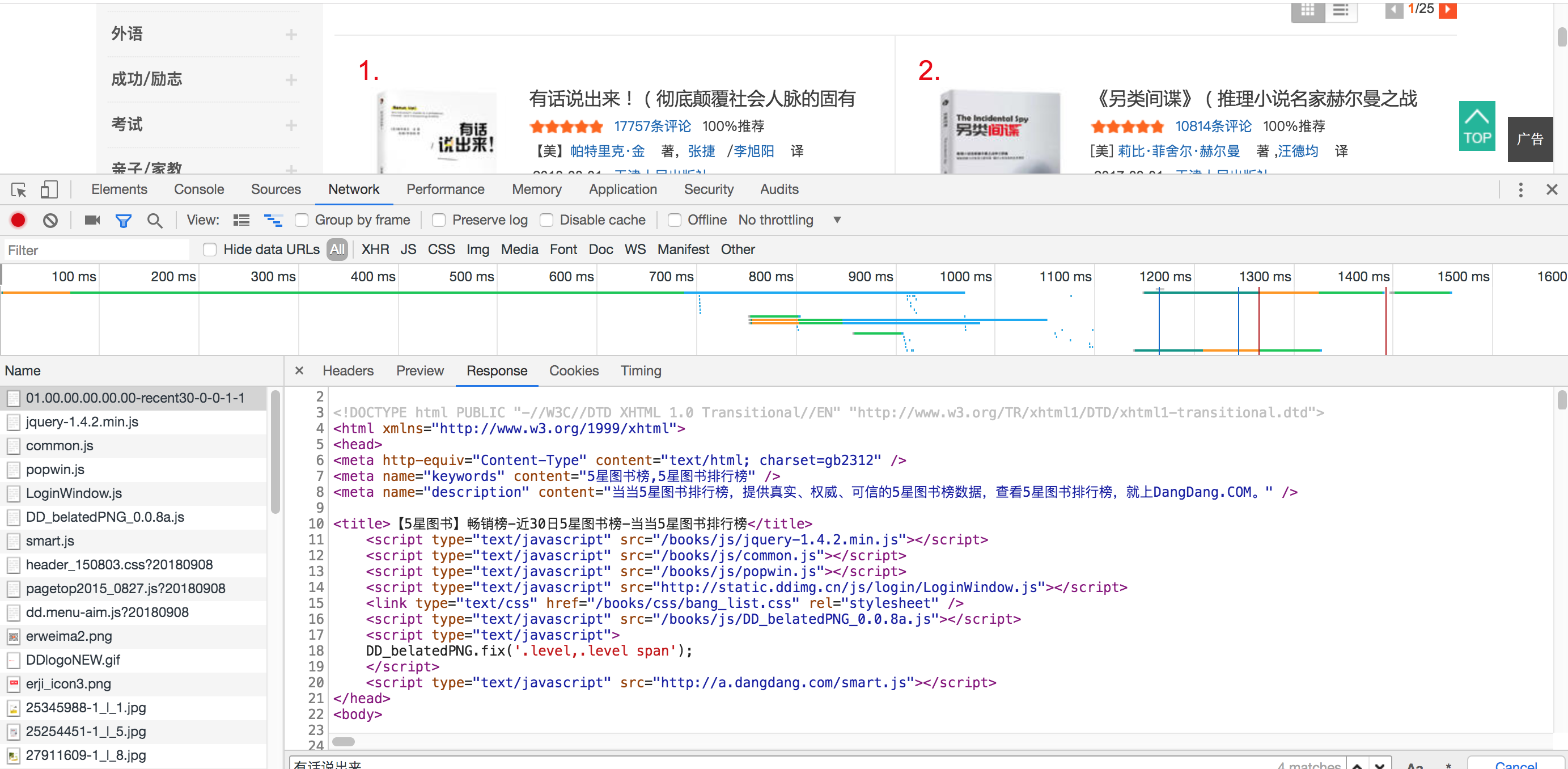
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API协议解析器java,只需少量代码即可实现一个功能强大的爬虫。除了爬虫框架,WebCollector还集成了CEPF,是目前最先进的网页内容自动抽取算法之一。
WebCollector致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有很强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了Jsoup,可进行精准的网页解析。jsoup 是一款 Java 的HTML 解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于JQuery的操作方法来取出和操作数据。
WebCollector内核构架图
它是一款开源爬虫,在github()上可查看相关源码,下载并导入项目,或使用Maven直接引入项目。
cn.edu.hfut.dmic.webcollector
WebCollector
2.72-beta
在源码cn/edu/hfut/dmic/webcollector/example/目录下有许多已经写好的例子,参考相关例子即可快速完成爬虫的编写。
DemoAutoNewsCrawler.java是一个新闻网站抓取的demo,其中的结构也很简单,仅包含三个方法。该类继承于BreadthCrawler类,需要重写visit方法即可实现抓取。Demo文件中所指向的网站url是github博客,只需改动其中的抓取网站的url及对应访问规则,就变成了另外一个新闻网站的爬虫了。
03
抓取辽宁省省市区等多级联动数据

辽宁省下设14市,每座城市都有对应的区或县,每个区县下设街道或乡镇,每个街道或乡镇又包含多个社区或村庄,通过中华人民共和国国家统计局 > 统计数据 > 统计标准 > 统计用区划和城乡划分页面选择对应年份进入。本例使用2019年相关公开数据。
()
通过分析,每一层级页面中会显示下一层级的统计用区划代码,除市辖区外,其余均可进行点击,直到社区、村一级后,不再包含下一层级。页面上相关元素也比较简单协议解析器java,全部内容均包含在tbody之中,便于进行抓取。
如在上述页面中,查看页面代码可知主要信息包括统计用区划代码及城市名称,每行数据被封装在一个class为citytr的tr组件中,可通过page的select方法进行数据循环筛选。
Element element = page.select("tr[class=citytr]").get(i);
从element中可找出对应的统计用区划代码及城市名称。

String code = element.select("td").get(1).html().split("/")[1].split(".html")[0];
String name = element.select("td").get(1).text();
其他页面内容基本类似,使用相同的方法即可进行抓取。
爬虫运行时可设置抓取深度,默认为crawler.start(4),可根据需求进行修改。
04
Robots协议

Robots协议也叫robots.txt,是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
Robots协议是国际互联网界通行的道德规范,基于以下原则建立:
1、搜索技术应服务于人类,同时尊重信息提供者的意愿,并维护其隐私权;
2、网站有义务保护其使用者的个人信息和隐私不被侵犯。
虽然爬虫能够访问并抓取对应网站页面的相关信息,但是仍要记得遵守Robots协议,尽可能的不影响所爬取网站的正常运行。
 上一篇
上一篇 








