

python识别验证码源码-python识别验证码源码

图片来自 unsplash
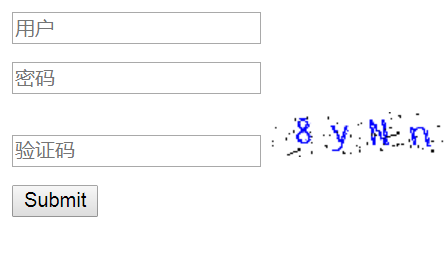
目前,很多网站为了防止爬虫肆意模拟浏览器登录,采用增加验证码的方式来拦截爬虫。验证码的形式有多种,最常见的就是图片验证码。其他验证码的形式有音频验证码,滑动验证码等。图片验证码越来越高级python识别验证码源码,识别难度也大幅提高,就算人为输入也经常会输错。本文主要讲解识别弱图片验证码。
1 图片验证码强度
图片验证码主要采用加干扰线、字符粘连、字符扭曲方式来增强识别难度。
其中最弱的验证码为不具备以上的特征,干扰因素比较小。如下:
2 识别思路

首先对图片做二值化来降噪处理,去掉图片中的噪点,干扰线等。然后将图片中的单个字符切分出来。最后识别每个字符。
图片的处理,我采用 Python 标准图像处理库 PIL。图片分割,我暂时采用谷歌开源库 Tesseract-OCR。字符识别则使用 pytesseract 库。
3 安装
我使用的 Python 版本是 3.6, 而标准库 PIL 不支持 3.x。所以需要使用 Pillow 来替代。Pillow 是专门兼容 3.x 版本的 PIL 的分支。使用 pip 包管理工具安装 Pillow 是最方便快捷的。
pip install Pillow
# 如果出现因下载失败导致安装不上的情况,建议使用代理
pip --proxy http://代理ip:端口 install Pillow
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后经由Google进行改进,消除bug,优化,重新发布。这才让其重焕新生。
我们可以在 GitHub 上找到该库并下载。我是下载最新的 4.0 版本。
github 的下载地址
pytesseract 是 Tesseract-OCR 对进行包装,提供 Python 接口的库。同样可以使用 pip 方式来安装。
pip install pytesseract
# 如果出现因下载失败导致安装不上的情况,建议使用代理
pip --proxy http://代理ip:端口 install pytesseract
4 代码实现4.1 获取并打开图片
获取图片验证码,你可以通过使用网络请求库下载。我为了方便,将图片下载到本地并放在项目目录下。
from PIL import Image
'''
获取图片
'''
def getImage():
fileName = '16.jpg'
img = Image.open()
# 打印当前图片的模式以及格式
print('未转化前的: ', img.mode, img.format)
# 使用系统默认工具打开图片
# img.show()
return img
4.2 预处理
这一步主要是将图片进行降噪处理, 把图片从 "RGB" 模式转化为 "L" 模式,也就是把彩色图片变成黑白图片。再处理掉背景噪点,让字符和背景形成黑白的反差。
'''
1) 将图片进行降噪处理, 通过二值化去掉后面的背景色并加深文字对比度
'''
def convert_Image(img, standard=127.5):
'''
【灰度转换】
'''
image = img.convert('L')
'''
【二值化】
根据阈值 standard , 将所有像素都置为 0(黑色) 或 255(白色), 便于接下来的分割
'''
pixels = image.load()
for x in range(image.width):
for y in range(image.height):
if pixels[x, y] > standard:
pixels[x, y] = 255
else:
pixels[x, y] = 0
return image

打开彩色图片,PIL 会将图片解码为三通道的 “RGB” 图像。调用 convert('L') 才会把图片转化为黑白图片。其中模式 “L” 为灰色图像, 它的每个像素用 8 个bit表示, 0 表示黑, 255 表示白, 其他数字表示不同的灰度。
在 PIL 中,从模式 “RGB” 转换为 “L” 模式是按照下面的公式转换的:
L = R 的值 x 299/1000 + G 的值 x 587/1000+ B 的值 x 114/1000
图像的二值化,就是将图像上的像素点的灰度值两极分化(设置为 0 或 255,0表示黑,255表示白),也就是将整个图像呈现出明显的只有黑和白的视觉效果。目的是加深字符与背景的颜色差,便于 Tesseract 的识别和分割。对于阈值的选取,我采用比较暴力的做法,直接使用 0 和 255 的平均值。
4.3 识别
经过上述处理,图片验证码中的字符已经变成很清晰了。
最后一步是直接用 pytesseract 库识别。

import pytesseract
'''
使用 pytesseract 库来识别图片中的字符
'''
def change_Image_to_text(img):
'''
如果出现找不到训练库的位置, 需要我们手动自动
语法: tessdata_dir_config = '--tessdata-dir ""'
'''
testdata_dir_config = '--tessdata-dir "C:\\Program Files (x86)\\Tesseract-OCR\\tessdata"'
textCode = pytesseract.image_to_string(img, lang='eng', config=testdata_dir_config)
# 去掉非法字符,只保留字母数字
textCode = re.sub("\W", "", textCode)
return textCode
Tesseract-ORC 默认是没有指定安装路径。我们需要手动指定本地 Tesseract 的路径。不然会报出这样的错误:
FileNotFoundError: [WinError 2] 系统找不到指定的文件
具体解决方案是:
使用文本编辑器打开 pytesseract 库的 pytesseract.py 文件,一般路径如下:
C:\Program Files (x86)\Python35-32\Lib\site-packages\pytesseract\pytesseract.py
将 tesseract_cmd 修改成你电脑本地的 Tesseract-OCR 的安装路径。
# CHANGE THIS IF TESSERACT IS NOT IN YOUR PATH, OR IS NAMED DIFFERENTLY
tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'

最后执行字符识别的实例代码
def main():
img = convert_Image(getImage(fileName))
print('识别的结果:', change_Image_to_text(img))
if __name__ == '__main__':
main()
运行结果如下:
未转化前的: RGB JPEG
识别的结果: 9834
5 总结
Tesseract-ORC 对于这种弱验证码识别率还是可以,大部分字符能够正确识别出来。只不过有时候会将数字 8 识别为 0。如果图片验证码稍微变得复杂点,识别率大大降低python识别验证码源码,会经常识别不出来的情况。我自己也尝试收集 500 张图片来训练 Tesseract-ORC,识别率会有所提升,但识别率还是很低。
如果想要做到识别率较高,那么需要使用 CNN (卷积神经网络)或者 RNN (循环神经网络)训练出自己的识别库。正好机器学习很火爆很流行,学习一下也无妨。
上篇阅读:Python定时任务(下)
 上一篇
上一篇 








